
티스토리 뷰
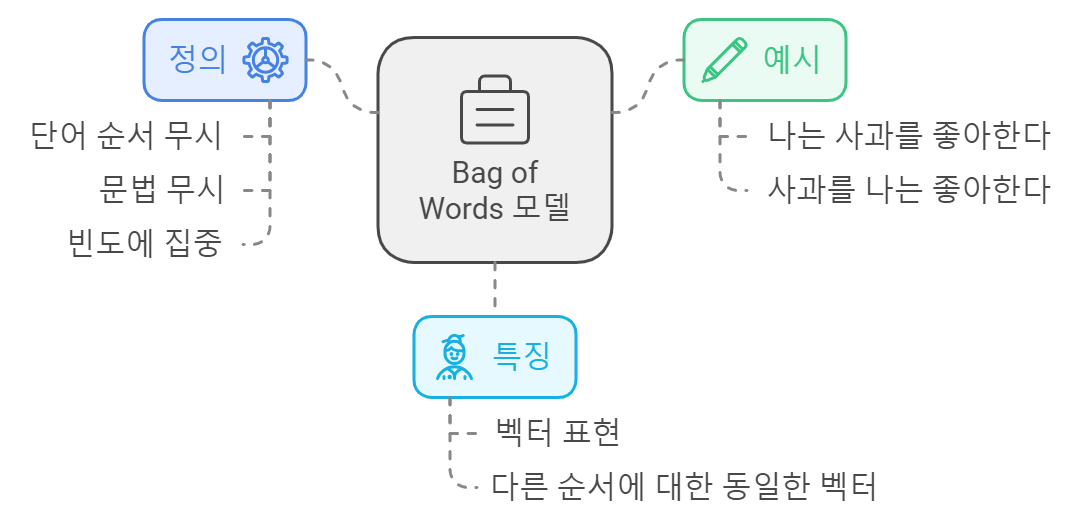
Bag of Words(BOW) 모델은 자연어 처리(NLP)에서 텍스트 데이터를 수치적으로 표현하는 간단하면서도 효과적인 방법입니다. 이 모델은 문서의 단어들을 "주머니"에 담아 단어의 순서를 무시하고 각 단어의 빈도만을 고려합니다. 이번 글에서는 Bag of Words의 기본 개념, 작동 원리, 장단점, 그리고 Python 예제를 통해 실제 구현 방법을 살펴보겠습니다.
1. Bag of Words의 기본 개념
Bag of Words는 텍스트를 벡터로 변환하는 방법입니다. 각 문서에서 단어의 순서는 고려하지 않으며, 단어의 출현 빈도만을 갖고 문서를 표현합니다. 이 모델은 다음과 같은 과정으로 진행됩니다:
- 단어 집합 생성: 문서에 등장하는 모든 단어를 수집하여 어휘(vocabulary)를 만듭니다.
- 문서 표현: 각 문서의 단어 빈도를 기반으로 벡터를 생성합니다.
예를 들어, 다음과 같은 두 문서가 있을 때:
- 문서 1: "고양이는 귀엽고 강아지는 사랑스럽다."
- 문서 2: "강아지는 귀엽고 고양이는 똑똑하다."
이 경우의 어휘는 ["고양이", "귀엽고", "강아지", "사랑스럽다", "똑똑하다"]가 됩니다.
2. Bag of Words 작동 원리
Bag of Words 모델은 다음과 같은 단계로 작동합니다:
Step 1: 단어 집합 생성
모든 문서에서 사용된 단어들의 목록을 만듭니다.
Step 2: 문서 벡터화
각 문서의 단어 빈도를 세어 벡터로 변환합니다.
3. 장점 및 단점
장점
- 간단함: 구현이 쉽고 이해하기 간단합니다.
- 효율성: 대량의 데이터를 처리할 때 빠르게 동작합니다.
단점
- 문맥 정보 손실: 단어의 순서나 문맥 정보를 무시하므로 의미를 완전히 반영하지 못할 수 있습니다.
- 희소성: 어휘가 커질 경우, 대부분의 단어가 문서에 등장하지 않아 희소 행렬이 생성될 수 있습니다.
4. Python 예제
이제 Python을 사용하여 Bag of Words 모델을 구현해 보겠습니다. 우리는 CountVectorizer를 사용하여 문서를 벡터로 변환할 것입니다.
필요한 라이브러리 설치
먼저 필요한 라이브러리를 설치합니다. scikit-learn 라이브러리를 사용하여 Bag of Words 모델을 구현할 수 있습니다.
bash
pip install scikit-learn
코드 예제
다음은 Bag of Words 모델을 구현하는 Python 코드입니다.
python
from sklearn.feature_extraction.text import CountVectorizer
# 문서 리스트
documents = [
"고양이는 귀엽고 강아지는 사랑스럽다.",
"강아지는 귀엽고 고양이는 똑똑하다."
]
# CountVectorizer 객체 생성
vectorizer = CountVectorizer()
# 문서 벡터화
X = vectorizer.fit_transform(documents)
# 결과 출력
print("어휘 목록:", vectorizer.get_feature_names_out())
print("문서-단어 행렬:\n", X.toarray())
코드 설명
- 문서 리스트 생성: 분석할 문서들을 리스트로 정의합니다.
- CountVectorizer 객체 생성: CountVectorizer를 사용하여 BOW 모델을 위한 객체를 생성합니다.
- 문서 벡터화: fit_transform 메서드를 사용하여 문서를 벡터로 변환합니다.
- 결과 출력: 어휘 목록과 문서-단어 행렬을 출력합니다.
출력 결과
위 코드를 실행하면 다음과 같은 결과를 얻을 수 있습니다:
어휘 목록: ['강아지' '귀엽고' '사랑스럽다' '고양이' '똑똑하다']
문서-단어 행렬:
[[1 1 1 1 0]
[1 1 0 1 1]]
여기서 어휘 목록은 각 단어의 인덱스를 나타내며, 문서-단어 행렬은 각 문서에서 각 단어가 몇 번 등장했는지를 나타냅니다.
결론
Bag of Words 모델은 텍스트 데이터를 수치적으로 표현하는 간단하고 효과적인 방법입니다. 단어의 순서를 무시하고 각 단어의 빈도만을 고려함으로써 머신러닝 알고리즘에서 텍스트 데이터를 처리할 수 있게 합니다. 이 글에서 설명한 내용과 Python 예제를 통해 Bag of Words의 작동 원리를 이해하고, 실제로 구현해 볼 수 있기를 바랍니다. 다양한 자연어 처리 작업에서 Bag of Words를 활용하여 더 나은 결과를 얻을 수 있을 것입니다.
'자연어 처리' 카테고리의 다른 글
| Stanford Unv. Naive Bayes 교육자료 (1) | 2024.10.20 |
|---|---|
| 나이브 베이즈와 Bag of Words (BoW) 연결하기 (4) | 2024.10.15 |
| 나이브 베이즈(Naive Bayes) 알고리즘에 대한 이해 (3) | 2024.10.15 |
| 표제어 추출(Lemmatization)과 어간 추출(Stemming) 비교 (3) | 2024.10.02 |
| [TEXT Processing] 텍스트 전처리 : Preprocessing 3단계 (4) | 2024.10.02 |
- Total
- Today
- Yesterday
- 기술적분석
- chat gpt api 비용 계산
- chat gpt 모델별 예산
- Python
- 로또 1164회 당첨
- chat gpt 가격 예상
- 로또 ai
- 인공지능 로또 예측
- chat gpt 모델 api 가격 예측
- 자동매매로직
- 차트분석
- 1165회 로또
- 케라스
- 재테크
- chat gpt 모델 별 가격
- 토치비전
- 클래스형 뷰
- 자동매매
- 1164회 로또
- Numpy
- 주린이탈출
- 퀀트투자
- chat gpt 한국어 가격
- 주식공부
- 티스토리챌린지
- chat gpt 4o 예산
- 주식투자
- 골든크로스
- 오블완
- 장고 orm sql문 비교
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |